

巨量資料分析核心平台探討
作者/黃哲諄 [發表日期:2014/9/5]
Big Data介紹
Big Data被翻譯為巨量資料(或稱海量資料、大數據),從字面上來看只是很多資料的意思,然而更進一步了解它的定義時,方能了解全球資訊科技界掀起風潮的Big Data到底是在談什麼。根據Garnter定義:「巨量資料是一種具有大量性(Volume)、多樣性(Variety)、快速產生性(Velocity)的資訊,需要新的資料處理方式,用以幫助決策與改善生產流程。」Big Data的大量性特徵,意指需要分析的資料量很大,資料量規模無法經由人工精準的擷取、處理、分析而轉化成為有用的資訊;Big Data的多樣性特徵,意指需要分析的資料除了結構化資料外,還有非結構化資料;Big Data的快速產生性特徵,意指資料不是靜態的,而是每日隨時都會產生,資料分析速度需要趕得上資料產生的速度。這三個資料特徵,構成當今全球資訊科技界所討論的Big Data。
Big Data被譽為繼雲端運算後新的一波科技浪潮。根據Wikibon的Big Data市場調查,Big Data市場商機逐年遞增,其投資重點項目分別為:運算(Computing)、儲存(Storage)、分析應用開發(App & Analytics)和專業服務(Professional Services),並預測2017年的整體產值可以達到500億美元,如圖一。然而,不同產業的客戶對於Big Data的需求不一樣,如圖二。銀行與證券產業著眼於Big Data的大量性與快速產生性的資料特徵;多媒體與通訊產業著眼於Big Data的大量性與多樣性的資料特徵;政府單位著眼於Big Data的大量性和多樣性的資料特徵;工業與天然資源產業著眼於Big Data的大量性與快速產生性的資料特徵。科技大廠提出了各種產品,以滿足客戶對於Big Data不同面向的需求,目前主流的核心產品莫過於由Yahoo、Google與Facebook力推的Hadoop,各科技廠商均基植於Hadoop之上推出各類型Big Data應用產品。
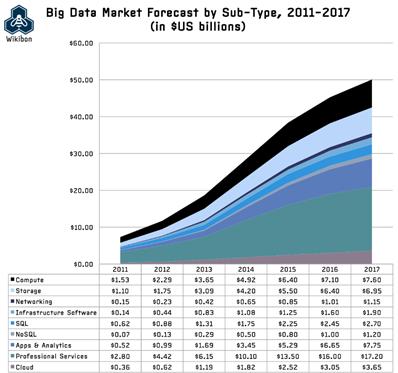
《圖一》Big Data市場預測

《圖二》各產業的巨量資料需求
Hadoop介紹
隨著網際網路的普及,越來越多人透過網路發佈消息,網路上的資料量呈現指數成長,而搜尋引擎公司Google卻沒有被這麼龐大的資料量擊倒,每天處理超過1 Petabyte的資料量,建立網頁索引提供使用者快速搜尋到網頁內容。事實上,全世界也沒有幾家公司能對如此龐大的資料量進行處理,尤其是網頁內容這種高度非結構化資料。人們一直在猜測,Google到底是怎麼辦到的?直到2003 與2004年間,Google發表了兩篇論文「The Google File System」和「MapReduce: Simplified Data Processing on Large Clusters」。這兩篇論文公布了Google的Big Data處理策略是透過「具有分散式運算能力的儲存系統」來完成,從此以後掀起了一波Big Data的浪潮,許多科技公司與開放程式碼社群爭相模仿實作出這套系統,最終成就了Hadoop,一個最接近Big Data全方位解決方案。
在Hadoop出現之前,企業處理Big Data的方式有三種:關聯式資料庫(Relation Databases)、資料倉儲(Data Warehouse)、網格運算(Grid Computing)。關聯式資料庫是一個很好的隨機存取儲存裝置,幾乎所有應用系統都會和關聯式資料庫結合,但它很少拿來儲存Petabyte等級的資料量,更不適合儲存非結構性資料;資料倉儲是關聯式資料庫的延伸,可以儲存Petabyte等級的資料,但需運作在大型主機上,故建置成本非一般企業能夠負擔;網格運算是利用多台伺服器同步做運算,以達到大型主機的運算能力,因具有水平擴充性,因此建置成本也比資料倉儲低很多。許多人會拿網格運算與Hadoop相比較,但兩者之間最大的相異處是,網格運算的運算裝置和儲存裝置是分開的,因此網格運算需要依賴SAN(Storage Area Network)來儲存與交換資料,一旦遇到巨量資料時,網路頻寬反而變成網格運算的瓶頸。
從一些案例中我們可以發現,Hadoop確實可以解決企業過去無法面對的問題。紐約時報(New York Times)決定將他們過去1851-1980年的所有報紙內容全部轉換成PDF檔,如此一來客戶就可以透過Web瀏覽報紙內容。為了要對新興網路媒體快速反擊,紐約時報選擇Hadoop來完成這項任務,令人興奮的是,所有的轉檔作業僅在一天內完成。摩根銀行(J. P. Morgan)在導入Hadoop前,已經有三萬台資料庫在處理日常的交易資料,然而他們還是沒有辦法處理非結構化資料,因此他們透過Hadoop來完成偵測商務詐欺。Facebook過去的Big Data分析是透過Oracle資料倉儲,然而隨著資料的成長,水平擴充性變成一個很重要的課題,如今現在Facebook已經有超過80%的分析是透過Hadoop來完成,並且成為Hadoop生態系的一份子。
Hadoop Solution Provider介紹
至今Hadoop生態系仍然相當活躍。由Facebook發起的Hive專案,提供類似SQL的操作介面,讓使用者可以使用SQL的方式來存取Hadoop的資料;由Yahoo發起的Pig專案,提供類似shell script的方式,讓使用者可以在不撰寫程式的情況下,用Hadoop運算;Sqoop專案提供ETL工具將資料庫的資料導入Hadoop中;Flume專案支援多種網路通訊協定,讓各種資料來源都可以放入Hadoop中;Oozie專案提供工作流的定義工具,讓多個工作可以整合在一起。即使Hadoop生態系相當地活躍,但還是令許多企業怯步,不敢擁抱這個新興的Big Data技術。最大的進入門檻障礙,就是版本相容問題,不同的開發社群各自為政,無法確定這個Hadoop集群中的所有套件都是穩定版本的,因此市場上出現了Hadoop專業服務公司,統一測試不同的Hadoop開發社群套件,然後再重新包裝成版本控管倉儲(Repository)給企業用戶。
知名的Hadoop專業廠牌有:Cloudera、Hortonworks、MapR。2014年初Intel花了7.4億美元,購買了Cloudera的18%股權;2014年中HP花了5000萬美元強化與Hortonworks的合作關係;2014年中MapR取得Google與Qualcomm的1.1億美元的資金挹注。如今三強鼎立的形式已形成,其中Cloudera是最早成立的Hadoop專業服務公司,擁有龐大知名的Hadoop顧問專家,例如:Tom White、Eric Sammer、Lars George…等,Cloudera在全球擁有超過400多個客戶,深獲市場好評。
Cloudera的Hadoop版本控管倉儲叫做CDH(Cloudera's Distribution, including Apache Hadoop),見圖三。使用者可以連接到Cloudera的CDH,直接透過yum的方式安裝Hadoop,不再需要到各個Apache Hadoop Project去下載編譯原始檔,大幅度地降低安裝配置難度。另外對企業用戶,Cloudera提供Cloudera Enterprise,強化Hadoop的安全機制,並可以透過單一介面安裝Hadoop的相關套件至數十台主機上,讓企業用戶可以更快速地建立Hadoop集群。Cloudera除了提供套件管理與集群管理軟體外,它還提供了教育訓練與專業認證服務,讓企業不需要擔心導入Hadoop之後,可能會有的人員教育訓練問題,當前可以從Cloudera取得的認證有Hadoop Admin CCAH、Hadoop Developer CCDH、CCP: Data Scientist和HBase Specialist CCSHB。

《圖三》Cloudera's Distribution, including Apache Hadoop
Cloudera對Hadoop是如此的專業,使得它可以將最新、最好、最成熟的技術提供給企業用戶。2014年CDH 5將Spark納入預設安裝項目,Spark是由柏克萊大學開發出來的分散式運算框架,與傳統的MapReduce相似,但使用記憶體來儲存中介資料(Resilient Distributed Dataset, RDD),使得處理的速度大為提升,將近是原本的MapReduce處理速度的100倍。雖然Spark需要更多的記憶體,但卻不用到像impala和stinger至少需要上百Gigabyte的記憶體擴充空間,讓企業客戶可以在合理的硬體投資上,顯著地提升運算速度。對於開發人員來說,Spark最大的吸引力莫過於程式撰寫更直覺,不需要把工作分別寫成Mapper和Reducer,大幅度地降低開發時間。由於Spark實在是太優秀了,知名的Hadoop機器學習專案──Mahout,已經於2014年停止提交MapReduce相關的程式碼,連同過去只支援MapReduce轉換的Hive專案,都於2014年開始支援Spark。藉由Cloudera的建議,我們可以預期Spark將會越來越熱門,甚至有可能會超越MapReduce。
次世代企業巨量資料分析平台
以Cloudera為核心打造企業Big Data全方案解決方案是相當正確的,然而只有Cloudera是不夠的。Hadoop在少量資料的回覆時間表現,是令人失望的,即便使用Cloudera的impala也只能做到接近即時性(nearly real-time)的表現,與傳統關聯式資料庫的毫秒級回覆時間,仍然有一段落差。事實上,Hadoop本來就是設計拿來回答大問題的,而非小問題的頻繁詢問,典型的大問題例如:20年來的每日平均銷售額是多少?然而對於企業而言,很難只因為大問題就打造一個具有Big Data處理能力的資料中心,投資項目的資產收益率(Return On Assets, ROA)需要達到一定水準,才能夠通過財務審核。因此,凌群基於Cloudera Enterprise Data Hub的概念,提出次世代企業巨量資料分析平台架構,如下圖四。
凌群電腦在打造次世代企業巨量資料分析平台時,我們考量的要素分別為:具水平擴充性、能處理Big Data、能夠接收與發布Open Data、具資料探勘(Data Mining)能力、豐富的視覺化呈現、快速回覆查詢。Cloudera Hadoop具有水平擴充性,並且可以同時滿足Big Data三個維度的需求;HP Vertica具有快速、水平擴充彈性、資料探勘能力;Tableau、QlikView等擁有絕佳的視覺化呈現效果;Informatica、Syncsort、MS SSIS等是ETL市場的主流領導者;對於統計專家而言,Cloudera Hadoop內建的Mahout可能不太夠用,因此我們將【R語言】整合進Cloudera Hadoop中,期望能從龐大的資料中得到有用的資訊,並將這些資訊釋出給工程師們使用,甚至是成為Open Data,以達到資料的再使用的理念。

《圖四》次世代企業巨量資料分析平台
參考文獻
‧http://www.gartner.com/newsroom/id/1731916
‧http://wikibon.org/wiki/v/Big_Data_Vendor_Revenue_and_Market_Forecast_2013-2017
‧https://www.gartner.com/doc/2077415/market-trends-big-data-opportunities
‧http://dl.acm.org/citation.cfm?id=945450
‧http://research.google.com/archive/mapreduce.html
‧http://open.blogs.nytimes.com/2007/11/01/self-service-prorated-super-computing-fun/?_php=true&_type=blogs&_r=0
‧http://www.reuters.com/article/2014/03/31/us-intel-cloudera-idUSBREA2U0ME20140331
‧http://www.zdnet.com/hp-invests-50-million-in-hortonworks-forges-big-data-partnership-7000031965/
‧http://www.mapr.com/company/press-releases/mapr-closes-110-million-financing-led-google-capital
‧http://spark.apache.org/
‧https://mahout.apache.org/
‧http://blog.cloudera.com/blog/2014/07/apache-hive-on-apache-spark-motivations-and-design-principles/
創新者的解答, 克雷頓.克里斯汀生(Clayton M. Christensen), 天下雜誌