

淺談海量資料
作者/陳明達 [發表日期:2014/6/23]
前言
這一兩年來海量數據(Big Data)的議題越來越常被提起,不管是在學術界還是企業界,海量數據似乎已經成為下一個兵家必爭之地。在科技業的題材洪流沖刷下,是不是能夠被洗鍊的大放異彩,又或者只是會淪為另一場技術空談的假象,本文會從海量數據的定義以及未來可能的應用面進行一些探討,身處在瞬息萬變的吞世代,海量數據的應用和可能的未來發展都值得我們密切關注,也許下一波科技革命浪潮的種子,就埋在這片大海中,等著我們去發掘。
什麼是海量數據
海量數據,顧名思義就是大量的數據資料,這對我們來說,是一個很抽象的概念,所謂的海量是要到多少才能夠稱為海量數據?而資料量從一些資料變成很多資料,這中間的差別又能帶給我們甚麼樣的啟發?在網路上,對於海量數據的定義有千千百百種,其中我覺得分析的精闢又很有道理的定義是「大量(Volume)且多元(Variety)並具備真實性(Veracity)的資料,必須以高時效(Velocity)完成取得、分析、處理、保存」。這一句話相當清楚的點出了海量數據的基本特質。首先,大量的定義與我們所認知的有些許出入,所謂的大量更精確的來說是指完整的資料集,當然完整之餘資料量越多對於分析後的判讀也會有更多意想不到的結果,而在這大量的資料中必須要保證資料的多樣性以及真實性,如果資料內容中帶有捏造的數據,這對於結果會造成一定程度上的失真,再者多樣性的內容才能讓分析出來的結果更加客觀而不偏頗,最後,根據以往的經驗來看,數據量與處理的時間幾乎是線性關係,也就是說,當有更多的資料需要處理分析時,所花費的時間會相對的增加,不過隨著現在的科技進步及硬體的支援,多執行緒、平行運算等等的技術都可以讓我們在海量數據的處理更加快速,進一步達成高時效性的處理,符合以上這幾個特點就可稱為海量數據。
海量數據革命
介紹完什麼是海量數據後,你心中一定有個疑問,就算現在有能力可以收集到很多的數據,那又怎麼樣呢?頂多就是在分析資料時,從抽樣調查變成使用所有樣本的資料來分析,就是提升精確度吧!如果你只是這樣想,那就大錯特錯,舉例來說,谷哥在很早之前便發現,根據某個區域所搜尋的關鍵字,可預測疾病是否即將爆發,精確的程度更是令人咋舌,而速度更幾乎是與當地衛生署所發現的時機同步,這代表甚麼?谷哥不需要挨家挨戶收集檢體,僅利用民眾上網搜尋的關鍵字,某種既定的模式,就可以預測某地是否即將爆發出現流感或疾病,當然,這跟民眾習慣上網找答案行為息息相關,而正是這種行為,造就了今天海量數據的統計以及分析出的結果往往可以帶給我們意想不到的新發現。
這些海量數據所帶給我們的創新體驗其實就發生在你我的身邊,如電子信箱垃圾郵件的過濾,約會網站的配對,上網時搜尋條件的建議以及廣告的自動追蹤,還有翻譯軟體的翻譯結果越來越能很直覺得讓人理解,等等......。這些都是資料革命下的產物,事實上已經發生,而且在不久的未來,更大動作的革新也會出現,舉凡自動駕駛的車輛,機器可以自動學習的人工智慧,海量數據的所會帶來的影響絕對遠遠超出你我的想像,可預知的是,這將會是一個推翻舊有思維,舊有生活模式,甚至於思考方式的全面改革。
NoSQL
在海量數據崛起的同時,隨之而來的改變之一就是資料庫的革命,關聯式資料庫概念並不適用於海量數據的應用。所以,NoSQL也漸漸成為討論海量數據時重要的核心概念之一,而NoSQL又是甚麼呢? 參考NoSQL Distilled中的定義,簡單的來說,當某資料庫套用NoSQL時,代表的意義是開放原始碼、多數在21世紀早期被開發並且多數是不使用SQL的未被完善定義、無綱要式的資料庫集合。NoSQL提供了更符合應用程式所需的資料模型,簡化了程式與資料庫之間的對應,進而提升應用程式開發的生產力。NoSQ的設計在叢集之上執行是最能展現出優勢的,所以如果是大規模的資料量,使用 NoSQL 較傳統的關聯性資料庫更為適合。而對於程式開發者來說,發展程式的過程就是要找到一個具有生產力的程式模型,這個資料模型適用於我們的應用程式,並且保證能夠取得所需的資料存取效能還能保有彈性。
傳統關聯式設計及聚集性思考設計
傳統關聯性資料庫將對應良好的各個元素以及他們之間的關係都完整了紀錄下來,但並無法區別代表聚集的關係,也就無法使用聚集結構的方式來儲存並且分配資料。而NoSQL的崛起,正是呼應使用聚集結構來儲存資料的派別,其中,應用在叢集上的執行,會更顯優勢,藉由定義清晰的聚集,就可得知有哪些資料是一起被維護,進而將這些資料放在同一節點上,讓資料存儲管理變容易。參考搞懂NoSQL Distilled一書中的範例,將可以更清楚的了解這兩者的差別,以下將以書中一訂單的範例作簡單說明:
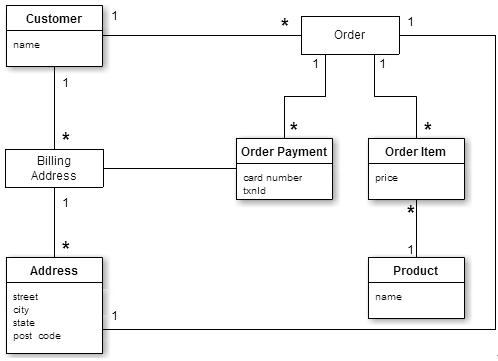
《圖一》關聯式資料庫的資料模型
從圖一來看,這是一個可以儲存關於使用者、商品型錄、訂單、寄送位址、帳單位址以及付款資料等資訊的關聯式資料庫模型。
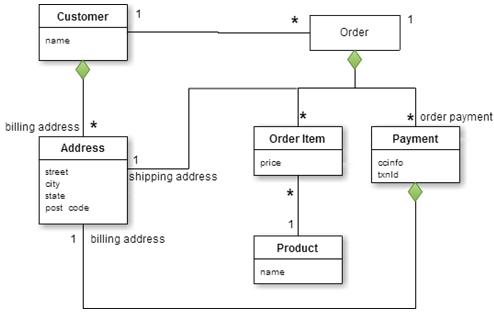
《圖二》聚集資料模型
從圖二中可得知有兩個主要的聚集,Customer 以及 Order。Customer包含了帳單地址的列表,Order包含了下訂物品的列表、寄送地址以及付款資料。付款資料本身包含了該付款的帳單地址。Order 與 Customer 只存在聚集之間的關係,而不存在同一個聚集之中,目的在於跟資料互動時所存取的聚集數量要最小化。看完了關聯性資料庫模型以及聚集資料模型後,相信應該會於這兩者的差別有一定的了解,設計資料模型的結果沒有絕對,尤其是聚集的邊界定義是更加沒有標準答案,所以在設計時就必須要思考如何存取資料以及對應的模型設計。
隱藏在海量數據背後的黑暗面
關於海量數據的思考,其實也是一體兩面的,完整且大量的數據分析結果固然可以帶給我們一些不一樣的方向,但同時,要思考的一點是蒐集來的資料可能是完全沒有意義的,在這個假說底下,海量數據的結果就可能會出現非常嚴重的錯誤預測,例如新聞報導出了某個疾病在某國家大爆發,這時看到新聞的人就會上網去查找疾病爆發的相關資訊,如果根據這個資訊去做分析,就可能會造成誤判。另外,在來源資料的蒐集也是需要特別注意的,一旦資料源頭出現抽樣錯誤的狀況或者不夠客觀的抽樣誤差,都會導致毀滅性的結果,這真的要特別小心。綜觀以上,雖然海量數據強調的是不管因果關係的相關性分析,但如果完全拋棄因果關係,將會徹底使海量數據內涵的意義來源被擊垮,如何取得這之間的平衡,也將是未來的一大課題。
對大部分人來說,海量數據核心價值之一就是以相關性作為預測的根據,預測疾病即將爆發的區域,根據人體健康檢查報告預測是否即將生病,機器設備是否即將出現狀況,提早發出故障或生病預警,甚至於如果應用在監獄系統上,說不定也可預測未來假釋出獄的罪犯,再犯的機會有多高,簡單來說就是預測犯罪。但從這個角度來看,因為預測的概念,未來的人們將會因此失去自主做決定並且負責的能力,抹煞了所有人的良知抉擇和自由意志,倫理道德都被預測未來的演算法取代,這將會導致另一種過度依賴機器而使得人們喪失判斷意志和選擇自由的可怕現象,相當值得深思。
結語
以往因為要分析大量資訊的計算能力以及儲存容量都太過昂貴,但在科技進步的現在,我們的想法也要跟上腳步,生活是可以被記錄、被量化的,使用資料的思維必須改變。大量的數據已經引發質變,如果我們還侷限在只看那些能夠收集來細細研究的資料,就是一種故步自封,只要能夠掌握大致的輪廓,就能抓住發展趨勢,從資料中找出事物的模式以及彼此的相關性,並從中取得創新見解,發掘隱藏在數據背後價值的智慧。
參考書目
‧http://www.dotblogs.com.tw/jimmyyu/archive/2013/03/07/big-data-analysis.aspx
‧Pramod J. Sadalage、Martin Fowler《搞懂NoSQL的15堂課》(NoSQL Distilled)。吳曜撰 譯。碁峰出版社,2013。
‧麥爾荀伯格、庫基耶《大數據》(Big Data)。林俊宏譯。天下出版社,2013。